
Grobble
Simple random search provides a competitive approach to reinforcement learning 본문
Simple random search provides a competitive approach to reinforcement learning
smilu97 2021. 8. 7. 00:32이 페이퍼는 2018년에 출판되었는데, Abstract를 보면 이 당시에는 policy의 parameter space를 직접 탐험하는 것이 action space를 탐험하는 것보다 훨씬 좋지 않다는 인식이 있었다고 한다. 여기서 소개되는 Augmented Random Search (ARS)는 policy parameter공간을 랜덤하게 탐험하면서 점진적으로 더 좋은 성과를 내도록 설계되어 있는데, 당시 비슷한 시기에 소개된 SAC와 견줄 정도의 sample efficiency를 가지고 있다고 주장된다.
Basic Random Search (BRS)
우선 ARS의 전신이 되는 알고리즘으로 Basic Random Search (BRS) 를 간단히 살펴보면,
BRS는 각 iteration마다 랜덤한 방향 N개를 생성해서 policy parameter를 아주 조금 움직여본다,

이 때, 랜덤 생성한 방향을 기존 것에 더해서 얻은 것과 빼서 얻은 것 2개의 보상을 보고 그 차이에 어떤 작은 값을 곱해서 기존 파라미터에 더해준다.
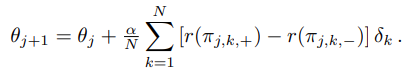
결과적으로, 해당 방향으로의 이동이 policy에 긍정적인 영향을 줄 수록 더 많이 그 방향으로 움직이게 되고, 반대로 부정적인 영향을 줄 경우 반대 방향으로 멀어지게 될 것이다.
Augmented Random Search (ARS)
ARS는 BRS에 두 가지 과정을 추가하는데, 하나는 state normalization, 또 다른 하나는 Using top performing directions 이다.
State normalization
두 개념 모두 굉장히 간단하고 말 그대로의 것을 수행한다. Policy에게 있어서 입력값이 되는 State의 여태껏의 평균과 분산을 항상 매번 업데이트 해주면서 추적하다가, 다음 State를 받으면 추적하던 평균과 분산을 이용해서 normalization 해준다.
Using top performing directions
BRS에서는 생성한 모든 방향들이 기존 Policy parameter를 적든 많든간에 움직이는데, ARS에서는 보상이 가장 높았던 N개의 방향들 외의 것들을 모두 무시한다.

Implementation
간단히 골자만 구현해보았는데 https://github.com/smilu97/ars
GitHub - smilu97/ARS
Contribute to smilu97/ARS development by creating an account on GitHub.
github.com
__init__.py 파일의 train 메소드를 보면 구현이 굉장히 간단하다. state normalization을 내부에서 구현하지 않고, 외부에서 받는 evaluator에서 구현하도록 의존하고 있다... 구조 상 이게 맞는 것 같은데 normalization에 대한 책임을 ARS 내부로 끌고 들어오는 것이 오히려 이상한 것 같다.
def train(self):
num_top_directions = self.config.num_top_directions
num_directions = self.config.num_directions
step_size = self.config.step_size
# Sample random directions to explore
diffs = self._select_random_diff(num_directions)
# Evaluate the rewards to get from exploring
params = np.concatenate([diffs, -diffs], axis=0) + self.params
rewards = np.array(self.evaluator(params), dtype=np.float64).reshape((2, -1)).transpose()
# Only b directions survive by their reward
sort_keys = [-max(r[0], r[1]) for r in rewards]
sort_indices = np.argsort(sort_keys)[:num_top_directions]
diffs = diffs[sort_indices]
rewards = rewards[sort_indices]
# Move parameters to the good enough directions
std_reward = np.std(rewards)
rewards = np.array([r[0] - r[1] for r in rewards], dtype=np.float64)
updates = rewards.reshape((-1, 1)) * diffs
mean_updates = np.mean(updates, axis=0)
update = (step_size / std_reward) * mean_updates
self.params += update
self.j += 1
'공부' 카테고리의 다른 글
| Classpath Index (0) | 2023.07.29 |
|---|---|
| Pinpoint 개발 환경 구축 (0) | 2022.01.29 |
| PCC, OCC에 대해서 (0) | 2021.09.02 |
| Sim-to-Real: Learning Agile Locomotion ForQuadruped Robots (0) | 2021.07.19 |

