
Grobble
Sim-to-Real: Learning Agile Locomotion ForQuadruped Robots 본문
https://arxiv.org/abs/1804.10332
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
Designing agile locomotion for quadruped robots often requires extensive expertise and tedious manual tuning. In this paper, we present a system to automate this process by leveraging deep reinforcement learning techniques. Our system can learn quadruped l
arxiv.org
Abstract
RL을 이용해 사족 보행 로봇을 학습 시키는데, 이 policy를 시뮬레이션 환경에서 계산을 통해 구한 다음 real world의 똑같이 구현된 로봇에서 적용시키는 데 겪을 수 있는 어려움을 해결하고, 동시에 open loop reference를 agent의 관찰값에 추가함으로서, 완전히 학습된 gait (걷는 모양) 보다는 좀 더 통제 가능한 모델을 만드는 것에 대해 소개한다.
Introduction
여기서 2가지 목표는 이렇다
- learning controllable locomotion policies
- transferring the policies to the physical system
여기서 controllability를 이루기 위해, open-loop reference를 agent에 제공할 것이다.
또 sim-to-real을 성공적으로 이루기 위해, reality gap을 줄인다는 표현이 자주 등장하는데, 이를 위해 physics simulation 자체의 재현도를 발전시키고, 센서 관측값에 random noise를 추가하거나, 로봇에 random한 힘을 지속적으로 가하거나, simulation parameter들에 random noise를 부여하는 등의 방법으로 policy의 robustness를 발전시킨다.
Robot platform and simulation
이 논문에서는 Ghost Robotics사의 Minitaur 로봇을 사용했다고 한다.
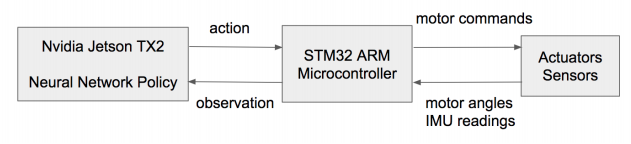
NN과 실제 Sensor, Actuator 레이어 사이에 마이크로 컨트롤러가 하나 중계하고 있어 Agent가 받을 state나 생성한 action을 알맞게 처리한다. 이 환경에서 Policy는 150Hz~200Hz 정도의 빈도로 action을 업데이트 할 수 있었다고 한다.
시뮬레이션은 PyBullet을 이용하여 제작했다고 하며, PPO 알고리즘을 사용했다고 한다.
Observation and Action Space
Observation을 compact하게 만드는 게 sim-to-real에 도움이 된다고 하는데, 예를 들어 minitaur의 경우 IMU의 yaw 측정값과, motor의 velocity측정값을 무시하는 게 도움이 되었다고 한다.
Action space를 설계할 때는 self-collision이 일어나지 않도록 제한하는 것이 중요한데, 이것이 action space의 valid한 영역 (self-collision이 일어나는 영역이나 관절 가동 범위를 벗어나는 영역을 제외한 곳)을 scattered, nonconvex하게 만들기 때문에 학습 난이도를 급증시킨다고 한다. 이 논문의 예시에서는 각 다리의 2개의 모터를 아래와 같이 움직였다고 한다. action으로 e, s가 각각 주어지면 theta1과 theta2를 두 관절의 목표 각도 (goal state)로 삼는다.
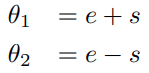
Reward function
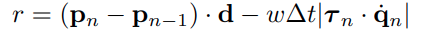
보상은 위치의 변화량에 이동할 방향을 내적한 것과 각 관절의 토크와 속도의 내적의 곱만큼 더한 것을 weighted sum 해서 사용했다고 한다. PPO 알고리즘이 w에 굉장히 robust하기 때문에 논문에서는 이 w를 특별히 tuning하지 않았다고 하는데, 0.008을 사용했다고 한다.
Policy representation
앞서 등장한 open-loop reference 라는 것을 observation (state) to action 함수에 포함시킨다.
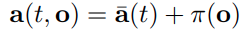
시간에 따라 고정된 출력을 제공하는 reference를 기존의 일반적인 state to action 함수에 섞어서 사용한다.
논문에서도 그렇게 길게 설명하지는 않았는데, 단순히 여기서 reference와 NN에서 출력된 policy에 가중치를 조절해서 어떤 term을 더 중요하게 둘 지 조절하는 정도의 엔지니어링이 가능하다.
Narrowing the reality gap
Improving simulation fidelity
기존 PyBullet에서 기본 제공하는 position controller가 실제 모터에서 사용하는 PD servo의 것과 매우 다르다는 점을 지적하고, 대안을 제시한다.
요약하자면, 실제 모터에서는 계산된 전류값과 실제 발휘되는 토크간에 비선형성이 존재하기 때문에 이것을 보정해야 한다는 것 같은데 잘 이해하지 못하겠다...
또 latency가 feedback control을 어렵게 만드는 주요 원인이라고 하는데, pyBullet 에서는 이 latency를 기본적으로는 고려하지 않도록 구현되어 있다. 즉, 시뮬레이션에서는 latency가 0라고 봐도 무방하다는 것인데, 이 어려움을 학습 과정에서 반영하지 못한다면 당연히 real world에서의 gap이 클 것이다.
이 real world에서의 latency를 모방하기 위해, observation의 히스토리를 관리해서 미리 설정한 latency만큼 과거의 기록 양쪽의 2개를 찾아 linear interpolation하여 사용했다고 한다.
Learning Robust Controllers
대략적으로, 랜덤 요소들을 이곳저곳에 삽입하여 Robustness를 발전시킨 policy를 학습하면 real world에서도 잘 작동할 것이라고 한다.

위의 표에 등장하는 것들과 같은 요소들을 uniform random하게 선택해서 바꿔가며 학습하는 것이다.
그리고 로봇에 랜덤한 흔들림을 부여해서 robustness를 증가시킬 수 있다고 하는데, 논문에서는 minitaur의 본체 부분에 1.2초마다(시뮬레이션 상에서) 0.06초동안 130~220N의 힘을 랜덤한 방향으로 주었다고 한다.
Evaluation
평가의 내용은 대부분 randomization이 sim위에서의 expected return은 낮았지만 real 에서의 return은 훨씬 높고 small observation이 마찬가지로 sim위에서는 large observation보다 열등한 모습을 보였지만 real 에서는 훨씬 잘한다는 내용이다.
'공부' 카테고리의 다른 글
| Classpath Index (0) | 2023.07.29 |
|---|---|
| Pinpoint 개발 환경 구축 (0) | 2022.01.29 |
| PCC, OCC에 대해서 (0) | 2021.09.02 |
| Simple random search provides a competitive approach to reinforcement learning (0) | 2021.08.07 |

